
Stable Diffusionなど画像生成AIを使用しているとLoRAという言葉をよく聞くと思います.
LoRAは学習済みモデルを自分好みに改良するような目的で使用されるものであり,特にStable Diffusionなどで使われる際は,特定のキャラに特化させモデルを作る目的で使用されることがほとんどです.
この記事では,自分用のLoRAを作成する方法を記載します.
LoRAとは?
LoRAは”Low-Rank Adaptation”の略で,LoRAに関する原論文はこちらです.
一言でいうと,LoRAはフルサイズのファインチューニングに比べて,はるかに高速で少ない計算量で学習が可能な技術です.
Stable Diffusion用に使う分にはTransformerやFine Tuning,LoRAの詳細を知る必要はありません.素人でも簡単に使えるというのがこの技術の素晴らしいところです.
技術に興味がある方は,Hugging Faceのブログにとても分かりやすく書かれているためご覧ください.↓



学習用データ
この記事では,AI学習用に東北ずん子のイラストを使用させて頂きます.
下記URLにアクセスし,「AI画像モデル用学習データ」をダウンロードします.

こんなかんじの画像↓が用意されています

sd-script
sd-scriptはLoRAの作成によく使用されているリポジトリです.
下記のような機能が実装されていますが,この記事ではLoRA用として使用します.
- DreamBooth training, including U-Net and Text Encoder
- Fine-tuning (native training), including U-Net and Text Encoder
- LoRA training
- Texutl Inversion training
- Image generation
- Model conversion (supports 1.x and 2.x, Stable Diffision ckpt/safetensors and Diffusers)

インストール方法
依存関係のインストール
まずは,GitとPython 3.10.6をインストールします.
AUTOMATIC1111を使用しているのであれば,すでにインストール済みのはずです.
インストールできていない場合,下記記事よりインストールしてください.
sd-scriptのインストール
Powershellを起動します.本記事では,Eドライブ直下で実行しています.
まず,sd-scriptsのGitリポジトリをクローンします.
git clone https://github.com/kohya-ss/sd-scripts.git
cd sd-scripts
次に,仮想環境(venv)を構築します.
python -m venv venv
.\venv\Scripts\activate
依存ライブラリのインストールや仮想環境へのファイルのコピーを行います.数分から十分程度要します.
python.exe -m pip install --upgrade pip
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
pip install --upgrade -r requirements.txt
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
下記コマンドで環境設定を行います.私の環境では下記のような設定としました.
accelerate config
------------------------------------------------------------------------------------------------------------------------In which compute environment are you running?
This machine
------------------------------------------------------------------------------------------------------------------------Which type of machine are you using?
No distributed training
Do you want to run your training on CPU only (even if a GPU is available)? [yes/NO]:
Do you wish to optimize your script with torch dynamo?[yes/NO]:
Do you want to use DeepSpeed? [yes/NO]:
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:
------------------------------------------------------------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)?
fp16
学習方法
sd-scriptsには下記の3つの方式が用意されています.
- DreamBooth、class+identifier方式
- DreamBooth、キャプション方式
- fine tuning方式
ここでは,fine tuning方式はコストが高すぎるため話題にはしません.
「DreamBooth、class+identifier方式」と「DreamBooth、キャプション方式」の特徴をまとめると下記のようになります.
| 方式 | 特徴 |
|---|---|
| DreamBooth、class+identifier方式 | 〇 キャプションファイル不要 × 特徴(髪型や服装など)も同時に学習してしまう →特徴をプロンプトで制御するのが難しくなる |
| DreamBooth、キャプション方式 | 〇 特徴の分離が容易 →髪型や服装などをプロンプトによって変化させやすい × キャプションファイルが必要 |
この記事では,「DreamBooth、キャプション方式」を採用します.その他の方式に関しては,作者のGitHubに記載されていますのでご覧ください.

学習の流れ
LoRAを学習の流れは次の通りです.
- 学習データの用意
- 設定ファイルの用意
- LoRA学習実行
- LoRA結果の確認
学習用のディレクトリは任意の名前で作成可能ですが,今回は”LoRA”というディレクトリを作成します.
“LoRA”ディレクトリの中にconfig.tomlという空のファイル,outputとdataという空のディレクトリを作成します.
作成後は下記のような階層構造となります.
E:\LoRA
├── config.toml
├── output/
└── data/
学習データの用意
冒頭に示したように,学習データとして「東北ずん子」を使用します.
こちらより「01_LoRA学習用データA氏提供版背景白」をダウンロードします.

“zunko”のディレクトリを確認すると下記のように「画像ファイル」と「テキストファイル」が用意されています.
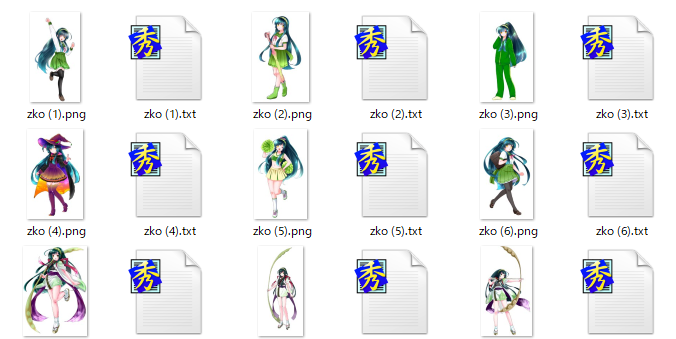
zko (1).txtの中身は下記のようにプロンプトがすでに用意されています.
zunko, 1girl, solo, skirt, one eye closed, thighhighs, standing on one leg, sailor collar, hairband, green skirt, school uniform, pleated skirt, green sailor collar, very long hair, shirt, black thighhighs, arm up, white shirt, white background, full body, smile, bangs, long sleeves, standing, shoes, brown footwear, simple background, serafuku, loafers, open mouth, looking at viewer, blush, ribbon, neck ribbon, ;d, zettai ryouiki, leg up, sailor shirt, blunt bangs
このファイルが「キャプションファイル」と呼ばれるもので,キャラクタの特徴等を示しているものです.
zunkoのファイルの中身をdataにコピーします.
E:\LoRA
├── config.toml
├── output/
└── data/
├── zko (1).png
├── zko (1).txt
├── zko (2).png
├── zko (2).txt
├── ...
├── zko (61).png
└── zko (61).txt
設定ファイルの用意
設定ファイルconfig.tomlを作成します.
config.toml
[general]
[[datasets]]
[[datasets.subsets]]
image_dir = 'E:\LoRA\data'
caption_extension = '.txt'
num_repeats = 10
基本的にはnum_repeatsを変更する程度で使い回しが効きますが,細かく設定変更をしたい場合は作者GitHubをご覧ください.
LoRA学習
学習用画像と設定ファイルが用意できたので,いよいよLoRA学習を行います.
LoRA学習は単純にコマンド実行するのみです.
accelerate launch --num_cpu_threads_per_process 1 train_network.py --pretrained_model_name_or_path='E:\stable-diffusion-models\Models\anything-v3.0\anything-v3-full.safetensors' --dataset_config='E:\LoRA\config.toml' --output_dir='E:\LoRA\output' --output_name='zunko' --save_model_as=safetensors --prior_loss_weight=1.0 --resolution=512,512 --train_batch_size=1 --max_train_epochs=10 --learning_rate=1e-4 --optimizer_type="AdamW8bit" --xformers --mixed_precision="fp16" --cache_latents --gradient_checkpointing --save_every_n_epochs=1 --network_module=networks.lora
RTX 2080 Superで二時間弱かかりました.
...
CUDA SETUP: Loading binary E:\sd-scripts\venv\lib\site-packages\bitsandbytes\libbitsandbytes_cuda116.dll...
use 8-bit AdamW optimizer | {}
override steps. steps for 20 epochs is / 指定エポックまでのステップ数: 12200
running training / 学習開始
num train images * repeats / 学習画像の数×繰り返し回数: 610
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 610
num epochs / epoch数: 20
batch size per device / バッチサイズ: 1
gradient accumulation steps / 勾配を合計するステップ数 = 1
total optimization steps / 学習ステップ数: 12200
steps: 0%| | 0/12200 [00:00<?, ?it/s]epoch 1/20
E:\sd-scripts\venv\lib\site-packages\torch\utils\checkpoint.py:25: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn("None of the inputs have requires_grad=True. Gradients will be None")
steps: 5%|||| | 610/12200 [05:31<1:44:55, 1.84it/s, loss=0.0995]saving checkpoint: E:\LoRA\output\zunko-000001.safetensors
epoch 2/20
steps: 10%||||||| | 1220/12200 [11:03<1:39:29, 1.84it/s, loss=0.0934]saving checkpoint: E:\LoRA\output\zunko-000002.safetensors
epoch 3/20
steps: 15%|||||||||| | 1830/12200 [16:35<1:34:02, 1.84it/s, loss=0.0852]saving checkpoint: E:\LoRA\output\zunko-000003.safetensors
epoch 4/20
steps: 20%|||||||||||| | 2440/12200 [22:08<1:28:35, 1.84it/s, loss=0.0952]saving checkpoint: E:\LoRA\output\zunko-000004.safetensors
epoch 5/20
steps: 25%||||||||||||||| | 3050/12200 [27:41<1:23:04, 1.84it/s, loss=0.0843]saving checkpoint: E:\LoRA\output\zunko-000005.safetensors
epoch 6/20
steps: 30%|||||||||||||||||| | 3660/12200 [33:15<1:17:35, 1.83it/s, loss=0.0884]saving checkpoint: E:\LoRA\output\zunko-000006.safetensors
epoch 7/20
steps: 35%||||||||||||||||||||| | 4270/12200 [38:48<1:12:05, 1.83it/s, loss=0.0838]saving checkpoint: E:\LoRA\output\zunko-000007.safetensors
epoch 8/20
steps: 40%||||||||||||||||||||||| | 4880/12200 [44:23<1:06:34, 1.83it/s, loss=0.0906]saving checkpoint: E:\LoRA\output\zunko-000008.safetensors
epoch 9/20
steps: 45%|||||||||||||||||||||||||| | 5490/12200 [49:56<1:01:02, 1.83it/s, loss=0.0882]saving checkpoint: E:\LoRA\output\zunko-000009.safetensors
epoch 10/20
steps: 50%|||||||||||||||||||||||||||||| | 6100/12200 [55:31<55:31, 1.83it/s, loss=0.0943]saving checkpoint: E:\LoRA\output\zunko-000010.safetensors
epoch 11/20
steps: 55%|||||||||||||||||||||||||||||||| | 6710/12200 [1:01:05<49:59, 1.83it/s, loss=0.0857]saving checkpoint: E:\LoRA\output\zunko-000011.safetensors
epoch 12/20
steps: 60%||||||||||||||||||||||||||||||||||| | 7320/12200 [1:06:39<44:26, 1.83it/s, loss=0.087]saving checkpoint: E:\LoRA\output\zunko-000012.safetensors
epoch 13/20
steps: 65%||||||||||||||||||||||||||||||||||||| | 7930/12200 [1:12:11<38:52, 1.83it/s, loss=0.0862]saving checkpoint: E:\LoRA\output\zunko-000013.safetensors
epoch 14/20
steps: 70%|||||||||||||||||||||||||||||||||||||||| | 8540/12200 [1:17:41<33:17, 1.83it/s, loss=0.0896]saving checkpoint: E:\LoRA\output\zunko-000014.safetensors
epoch 15/20
steps: 75%||||||||||||||||||||||||||||||||||||||||||| | 9150/12200 [1:23:11<27:43, 1.83it/s, loss=0.0801]saving checkpoint: E:\LoRA\output\zunko-000015.safetensors
epoch 16/20
steps: 80%||||||||||||||||||||||||||||||||||||||||||||| | 9760/12200 [1:28:41<22:10, 1.83it/s, loss=0.0894]saving checkpoint: E:\LoRA\output\zunko-000016.safetensors
epoch 17/20
steps: 85%||||||||||||||||||||||||||||||||||||||||||||||| | 10370/12200 [1:34:12<16:37, 1.83it/s, loss=0.0838]saving checkpoint: E:\LoRA\output\zunko-000017.safetensors
epoch 18/20
steps: 90%|||||||||||||||||||||||||||||||||||||||||||||||||| | 10980/12200 [1:39:43<11:04, 1.84it/s, loss=0.0832]saving checkpoint: E:\LoRA\output\zunko-000018.safetensors
epoch 19/20
steps: 95%||||||||||||||||||||||||||||||||||||||||||||||||||||| | 11590/12200 [1:45:13<05:32, 1.84it/s, loss=0.0822]saving checkpoint: E:\LoRA\output\zunko-000019.safetensors
epoch 20/20
steps: 100%|||||||||||||||||||||||||||||||||||||||||||||||||||||||| 12200/12200 [1:50:43<00:00, 1.84it/s, loss=0.0883]save trained model to E:\LoRA\output\zunko.safetensors
model saved.
steps: 100%|||||||||||||||||||||||||||||||||||||||||||||||||||||||| 12200/12200 [1:50:43<00:00, 1.84it/s, loss=0.0883]
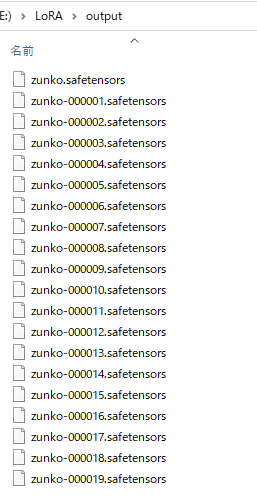
下記のように,LoRAファイルが出力されます.zunko.safetensorsが最終学習結果で,それ以外がEpochごとに出力した結果です.
出力間隔は--save_every_n_epochsで変更可能です.
学習用画像の枚数,エポック数,学習率やそのスケジューラなどによって学習結果は異なります.この辺りは基本的な深層学習と同様です.
いろいろと調整して良さそうなパラメータを調査してみてください.
LoRA結果の確認
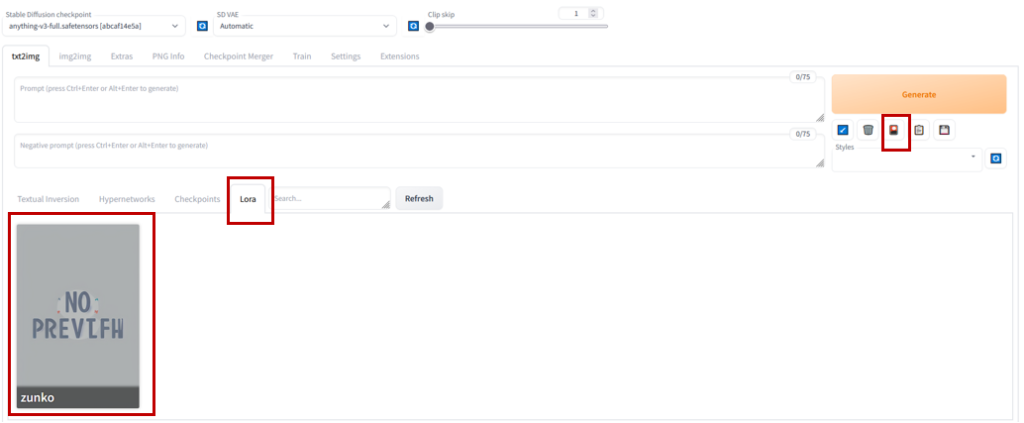
LoRAディレクトリ(/path/to/install/stable-diffusion-webui/models/Lora)に作成したLoRAファイル(zunko.safetensor)をコピーし,AUTOMATIC1111を起動します.
zunko用LoRAが作成されていることが分かります.
適当なプロンプト(zunko, <lora:zunko:1>, masterpiece,)で画像生成すると次のような画像が出力されます.十分に東北ずん子を学習できていると思います.

また,下記のように服装(制服や水着)なども自由に変更できるようになっています.



東北きりたんLoRA
東北ずん子以外にも東北きりたんでLoRAを作成してみました.

東北イタコLoRA
東北イタコLoRAも作成しました.


LoRA学習向けGPU
LoRAにはやはりそれなりのGPUが必要となってきます.
家庭用である程度有力なGPUを紹介しておきます.わりとメモリを使うので,それなりに積んでいるGPUがおすすめです.
演算能力よりもメモリ搭載量基準で価格を選ぶと良いと思います.
・長時間使用しなければ十分動作する性能のGPU

・快適に扱えるくらいの高性能GPU

・家庭用としては十分すぎるGPU(贅沢品)

さらに高額なNVIDIA A100やH100とかもありますが,もはや家庭用ではありません…
RTX4090など最新家庭用GPUは高価ですが,VRAM容量に限っていうと実はひと昔前のGPGPU向けGPUがお買い得だったりします.(演算向けなのでグラフィック出力がないので注意です)

