この記事では,MPIの関数であるMPI_Allgatherv()の説明とそのサンプルコードを示します.
MPI_Allgatherv
MPI_Allgathervとは
MPI_Allgatherv()は,各プロセスが異なるサイズのデータをすべてのプロセスと共有するための関数です.
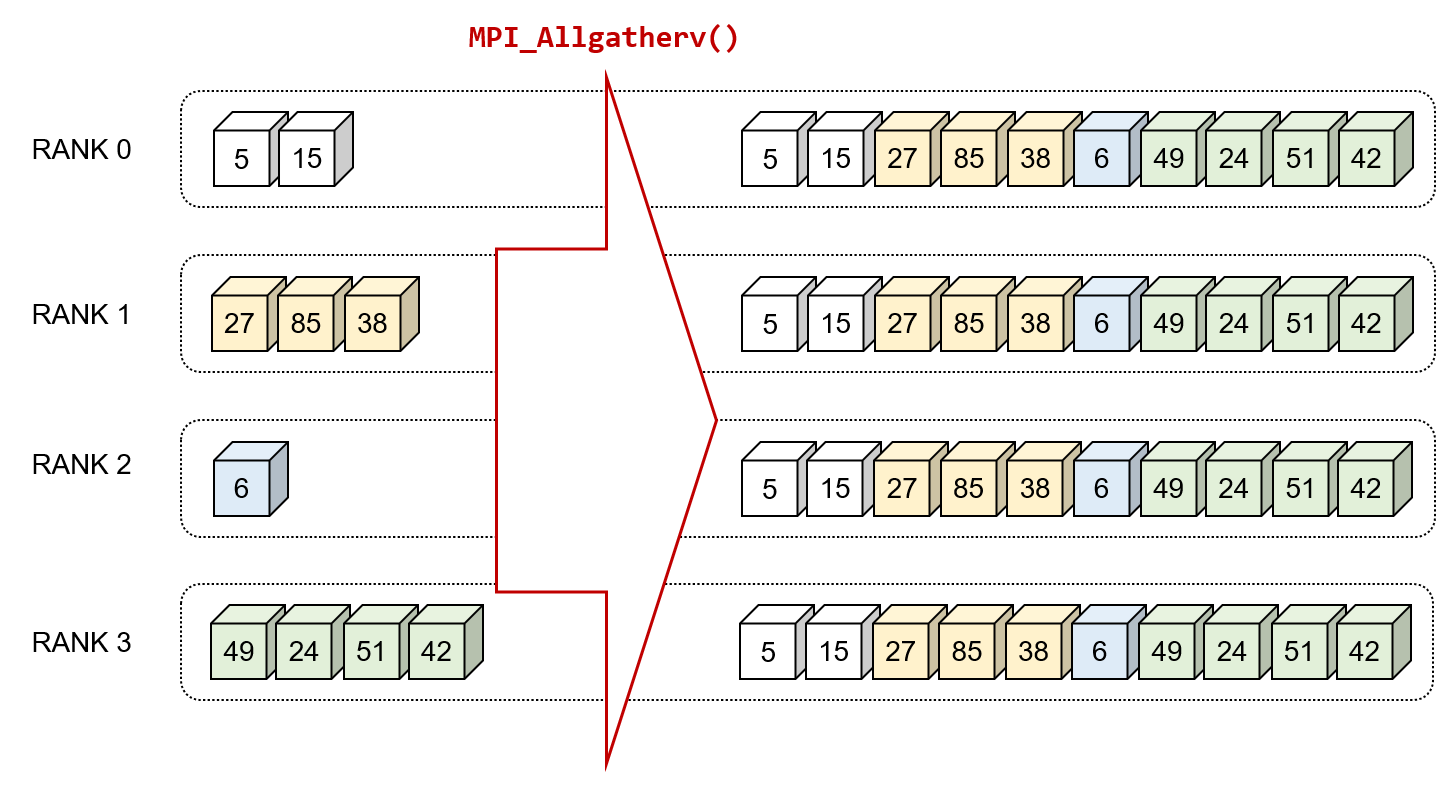
一例として,複数のプロセスがそれぞれ異なる量の数値データを持っている場面を考えます.各プロセスは,それぞれ次のような数値を保持しています.
- RANK 0 : {5, 15}
- RANK 1 : {27, 85, 38}
- RANK 2 : {6}
- RANK 3 : {49, 24, 51, 42}
このような場合,MPI_Allgatherv()関数を利用することで,すべてのプロセスが他のプロセスのデータも取得し,全てのデータを持つことができます.
このときの動作を具体的に視覚化すると,下図のようになります.
構文
MPI_Allgatherv()の構文を下記に示します.それぞれの引数は必須パラメータとなります.
int MPI_Allgatherv(const void *sendbuf,
int sendcount,
MPI_Datatype sendtype,
void *recvbuf,
const int recvcounts[],
const int displs[],
MPI_Datatype recvtype,
MPI_Comm comm);
- sendbuf
-
送信するデータの開始アドレス
- sendcount
-
送信するデータの個数
- sendtype
-
送信するデータの型
- recvbuf
-
受信データを保存するバッファの開始アドレスを
- recvcounts
-
各プロセスが受信するデータの個数を配列
- displs
-
受信バッファにおける開始位置を示す配列
- recvtype
-
受信データの型
- comm
-
コミュニケータ
MPI_Allgather()とMPI_Allgatherv()の違い
MPI_Allgatherv()は,非均質なデータ量を収集するための関数です.この関数は,MPI_Allgather()のより柔軟な関数として位置付けられており,各プロセスが異なるデータ量を送受信できるようになっています.
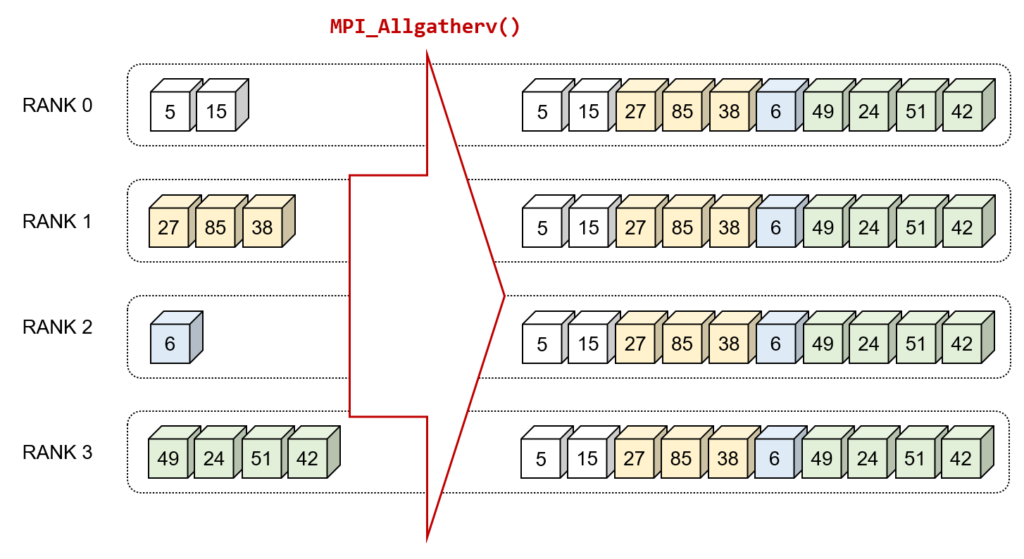
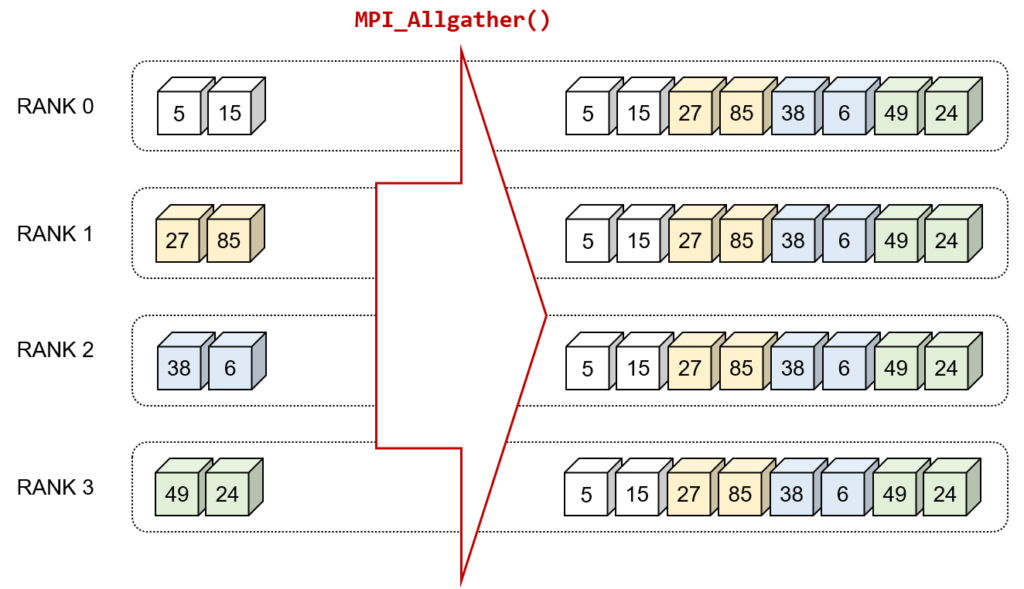
以下にMPI_Allgather()とMPI_Allgatherv()をそれぞれ図示しています.
MPI_Allgather()
すべてのプロセスが同じサイズのデータ(配列)を持っており,そのデータをすべての他のプロセスと共有したい場合に使用します.
MPI_Allgatherv()
各プロセスが異なるサイズのデータ配列を持っており,それを他のすべてのプロセスと共有したい場合に使用します。vは「可変」という意味で,各プロセスは異なるサイズのデータを共有できることを意味しています.
サンプルコード
例題として,上記に示した図の内容を実装してみます.各プロセッサの持つデータ配列は下記の通りです.
- RANK 0 : {5, 15}
- RANK 1 : {27, 85, 38}
- RANK 2 : {6}
- RANK 3 : {49, 24, 51, 42}
サンプルコード
main.cpp
#include <iostream>
#include <vector>
#include <mpi.h>
int main(int argc, char **argv)
{
int my_rank, num_procs;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
if (num_procs != 4)
{
MPI_Abort(MPI_COMM_WORLD, -1);
}
std::vector<int> send_data;
switch (my_rank)
{
case 0:
send_data = {5, 15};
break;
case 1:
send_data = {27, 85, 38};
break;
case 2:
send_data = {6};
break;
case 3:
send_data = {49, 24, 51, 42};
break;
}
std::vector<int> recv_counts(num_procs);
std::vector<int> displs(num_procs);
int send_size = send_data.size();
MPI_Allgather(&send_size, 1, MPI_INT, recv_counts.data(), 1, MPI_INT, MPI_COMM_WORLD);
int recv_size = 0;
int offset = 0;
for (int i = 0; i < num_procs; i++)
{
displs[i] = offset;
recv_size += recv_counts[i];
offset += recv_counts[i];
}
std::vector<int> recv_data(recv_size);
MPI_Allgatherv(send_data.data(),
send_data.size(),
MPI_INT,
recv_data.data(),
recv_counts.data(),
displs.data(),
MPI_INT,
MPI_COMM_WORLD);
std::cout << "my_rank " << my_rank << ": recv_data = ";
for (const auto &val : recv_data)
{
std::cout << val << " ";
}
std::cout << std::endl;
MPI_Finalize();
return 0;
}
CMakeLists.txt
cmake_minimum_required(VERSION 3.10)
project(example CXX)
find_package(MPI REQUIRED)main.cpp
add_executable(${PROJECT_NAME} main.cpp)
target_include_directories(${PROJECT_NAME} PRIVATE ${MPI_CXX_INCLUDE_PATH})
target_link_libraries(${PROJECT_NAME} PRIVATE ${MPI_CXX_LIBRARIES})
target_compile_options(${PROJECT_NAME} PRIVATE ${MPI_CXX_COMPILE_FLAGS})
付録
テンプレート関数化
C++で利用するときは,可変長配列が使えるため次のようなテンプレート化が容易に可能です.また,recvbuf, recvcounts, displsは自動的に計算可能なので省略可能です.
テンプレート関数
template<typename T>
MPI_Datatype get_mpi_datatype();
template<>
MPI_Datatype get_mpi_datatype<int>()
{
return MPI_INT;
}
template<>
MPI_Datatype get_mpi_datatype<double>()
{
return MPI_DOUBLE;
}
template<typename T>
std::vector<T> all_gather_data(const std::vector<T> &send_data)
{
int num_procs;
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
std::vector<int> recv_counts(num_procs);
std::vector<int> displs(num_procs);
int send_size = send_data.size();
MPI_Allgather(&send_size, 1, MPI_INT, recv_counts.data(), 1, MPI_INT, MPI_COMM_WORLD);
int recv_size = 0;
int offset = 0;
for (int i = 0; i < num_procs; i++)
{
displs[i] = offset;
recv_size += recv_counts[i];
offset += recv_counts[i];
}
std::vector<T> recv_data(recv_size);
const auto datatype = get_mpi_datatype<T>();
MPI_Allgatherv(send_data.data(),
send_data.size(),
datatype,
recv_data.data(),
recv_counts.data(),
displs.data(),
datatype,
MPI_COMM_WORLD);
return recv_data;
}