
この記事では,Stable Diffusionをさらに有名にした技術であるControlNetを導入します.
Stable Diffusionの導入
この記事を読まれている方でStable Diffusionのインストールをしていない方は少数だと思いますが,念のためWindowsへのインストール方法について記載した記事を載せておきます↓

アニメ風イラストの生成方法は下記記事


ControlNet 1.1で新しい機能が発表されました.そちらに関しては下記記事をご覧ください.
ポーズや構図に関するプロンプト
この記事ではControlNetについて記載していますが,プロンプトによってポーズや構図を指定することも可能です.
様々なポーズや構図に関するプロンプトは下記記事に記載しています.

ControlNetとは
ControlNetとは
ControlNetは,事前学習済みのモデルに対して新たに制約条件を与えることで,画像生成を柔軟に制御することが可能になる技術です.
すなわち,ControlNetによりimg2imgでは苦労していたポーズや構図の指定が可能になります.
AUTOMATIC1111でControlNetを使用するためには下記の2種類をインストールする必要があります.
- sd-webui-controlnet:AUTOMATIC1111でControlNetを使用するための拡張機能
- ControlNet:モデル本体
sd-webui-controlnetのインストール
まず,AUTOMATIC1111でControlNetを使用するための拡張機能を導入します.
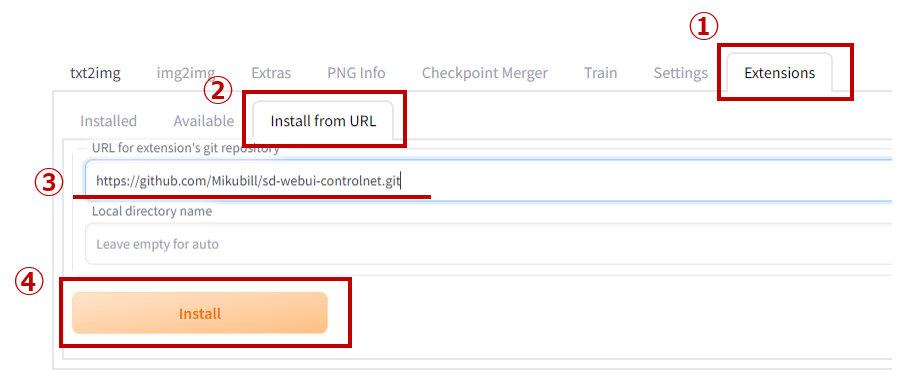
導入する拡張機能はhttps://github.com/Mikubill/sd-webui-controlnet.gitです.
下記のように,[Extensions] > [Install from URL]でURLを入力し,[Install]をクリックしてください.
しばらく待つとインストールが完了します.
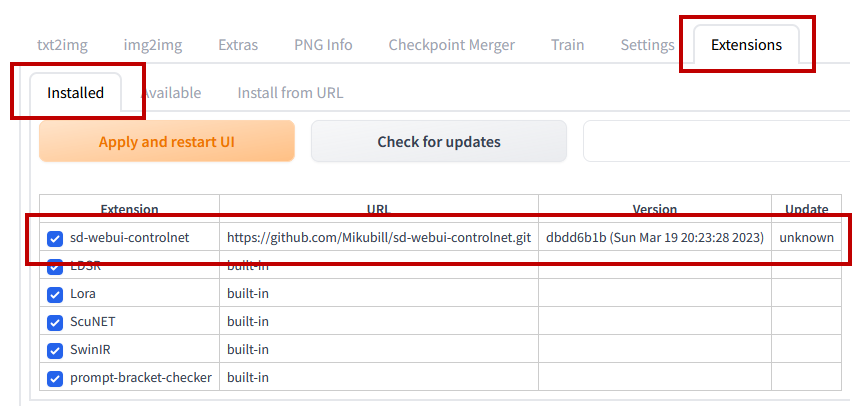
インストールが完了すると[Extensions] > [Installed]に”sd-webui-controlnet”が追加されているはずです.
また,ControlNetのプルダウンメニューが作成されています.
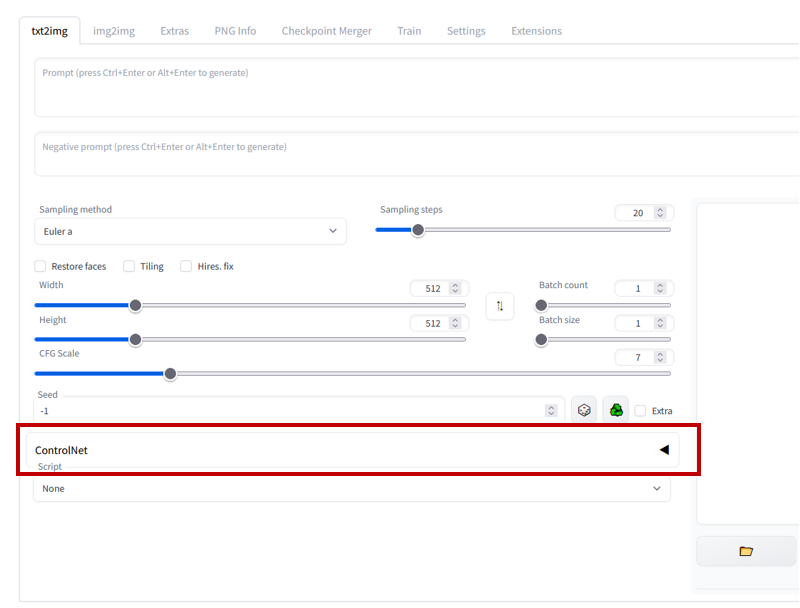
しかし,UIをインストールしただけなので,ControlNetのモデルが存在せず,使用できません.
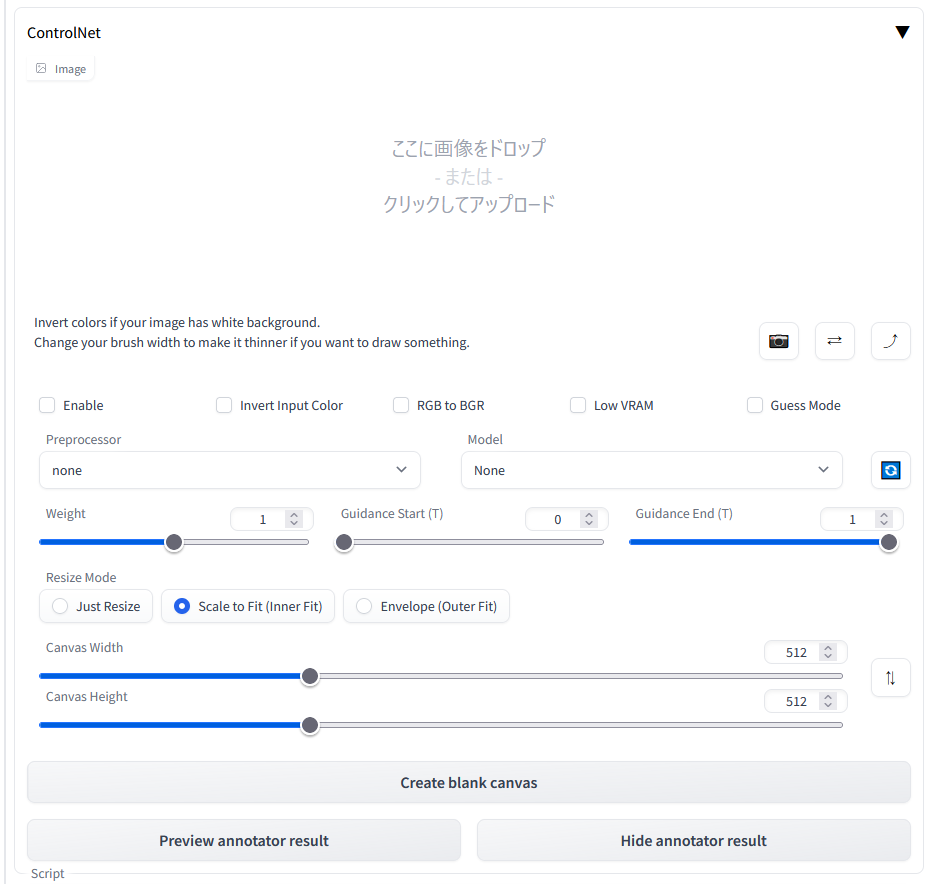
ControlNetのインストール
sd-webui-controlnetをインストールした後に,ControlNetのモデルを導入します.
下記,Hugging Faceにアクセスし「↓」からモデルをダウンロードします.
https://huggingface.co/lllyasviel/ControlNet/tree/main
/path/to/stable-diffusion-webui/extensions/sd-webui-controlnet/modelsにダウンロードしたモデルをコピーします.
コピーした後に再起動もしくは更新ボタンをクリックすると,下記のように”Model”にControlNetが反映されます.
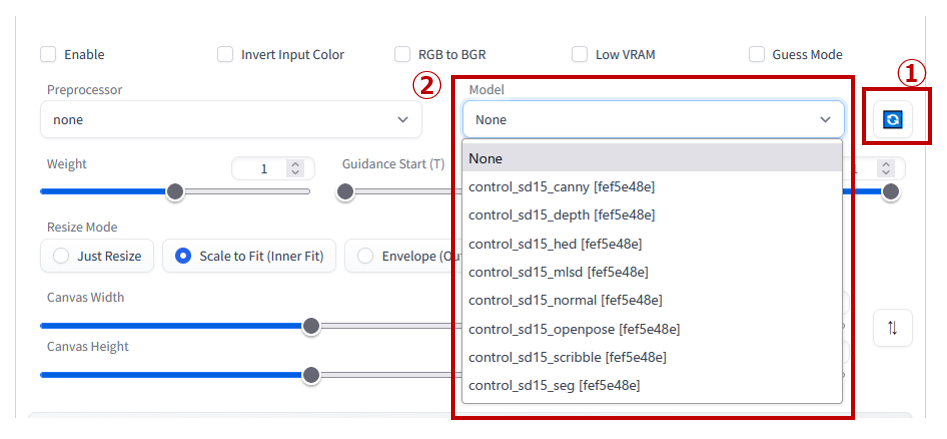
使い方
次に,ControlNetの使用方法に関して記載します.
ControlNetモデル
まずは実際に使う前に用意されているモデルに関して紹介します.
現在使用できるモデルは下記の8種類です.(2023/3/31現在)
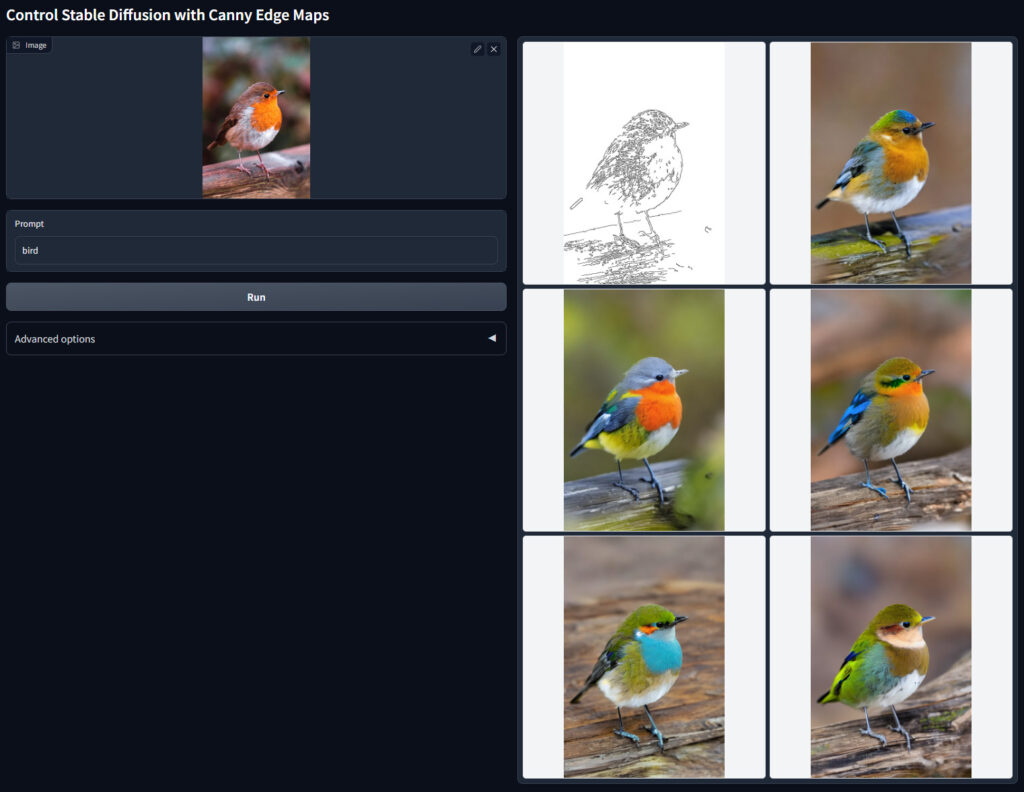
- canny
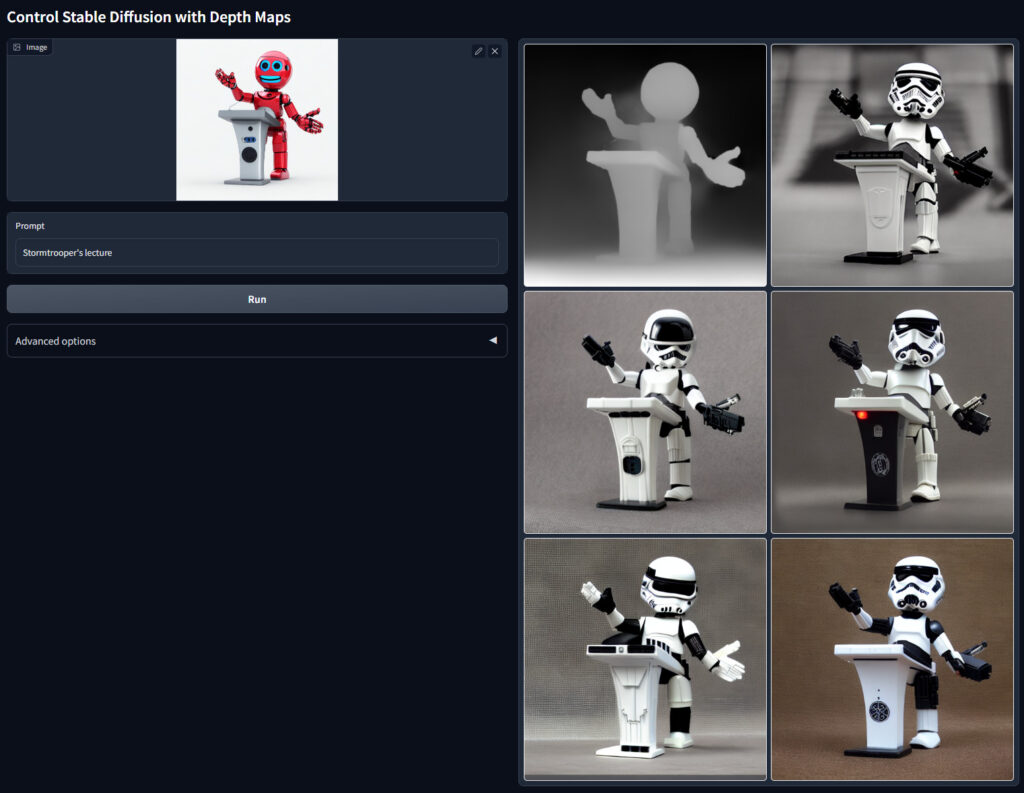
- depth
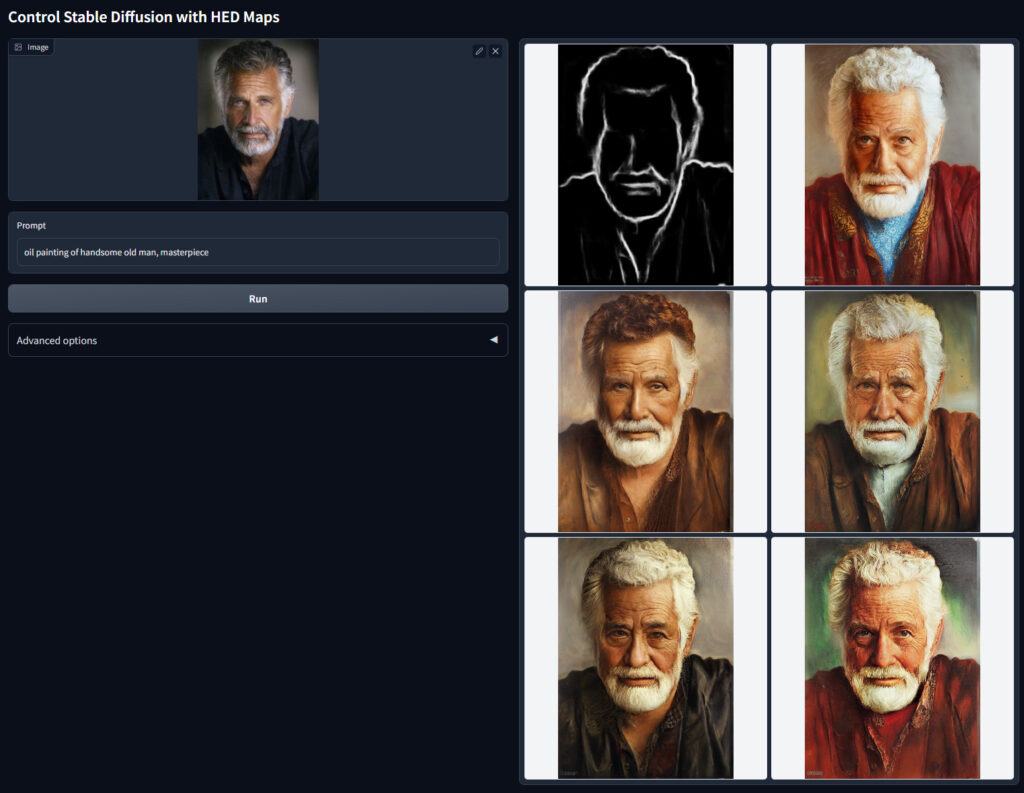
- hed
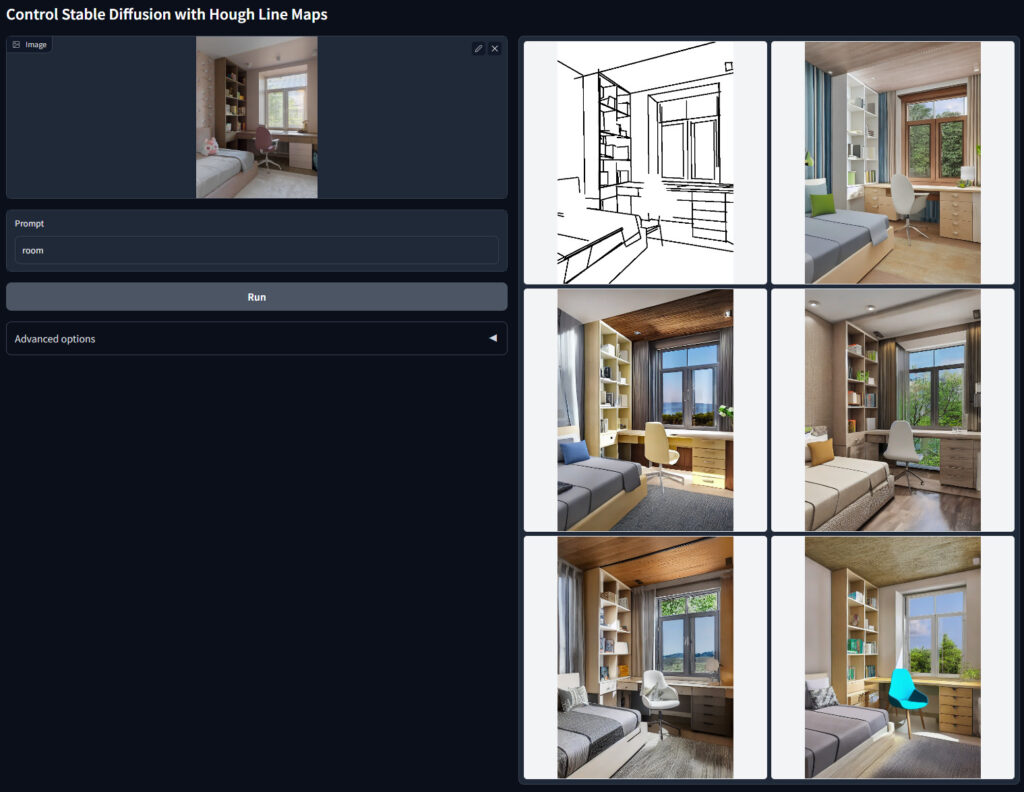
- mlsd
- normal
- openpose
- scribble
- seg
作者のGitHubでは9種類紹介されてますが,Anime Line Drawingに関しては使えないようになっています.
モデルの特徴を早見表にするとこんなかんじです.
| モデル名 | 説明 |
|---|---|
| canny | cannyはCanny edge detectionというアルゴリズムにより元画像から線画を生成し,その線画から新たにイラストを生成するモデルです.かなり忠実に再現されます. |
| depth | depthは画像を深度マップに変換し,それをベースに画像を生成するモデルです.奥行きが重要な構図の画像などで使用します. |
| hed | hedはcannyと同様に線画を作成し,線画からイラストを生成するモデルです. Cannyとの違いは,輪郭検出のアルゴリズムがHolistically-Nested Edge Detectionアルゴリズムに変更されている点です. Cannyだと細かい線を検出しますが,HEDの方が大まかな輪郭を抽出してくれます |
| mlsd | mlsdは直線の検出を行うモデルです.背景や構図に使用することが多いです. |
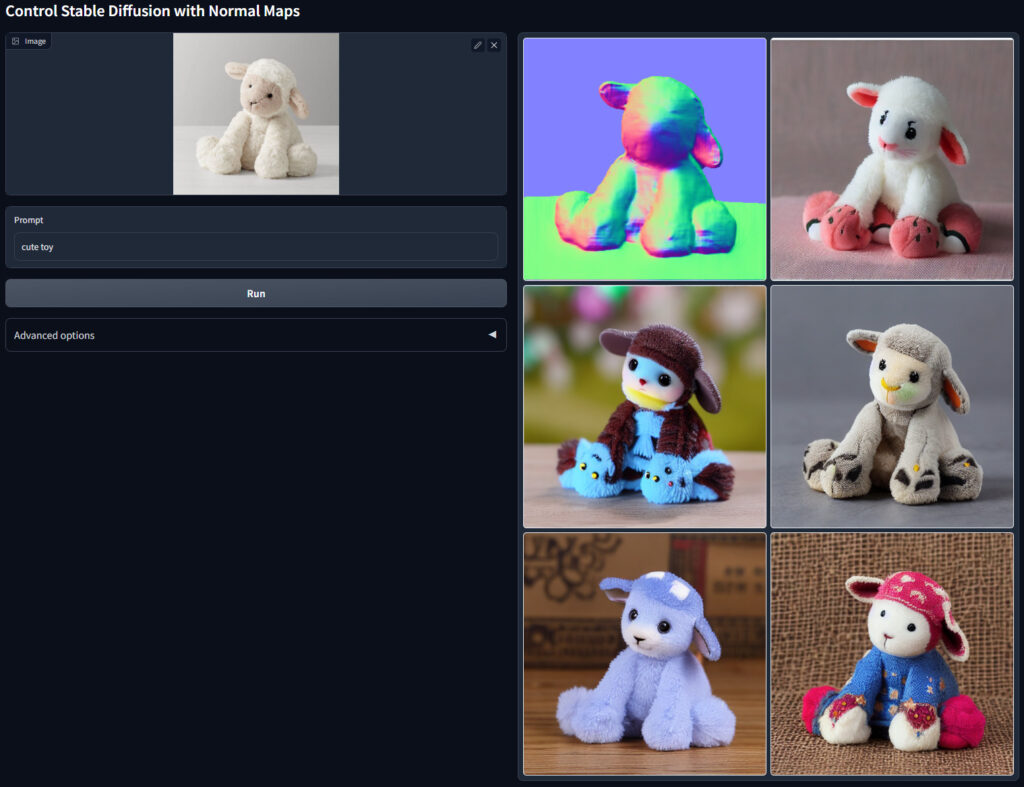
| normal | normalは,元画像を法線マップに変換し,法線マップから画像を生成するモデルです.(個人的にはdepthの方が使い勝手が良いです) |
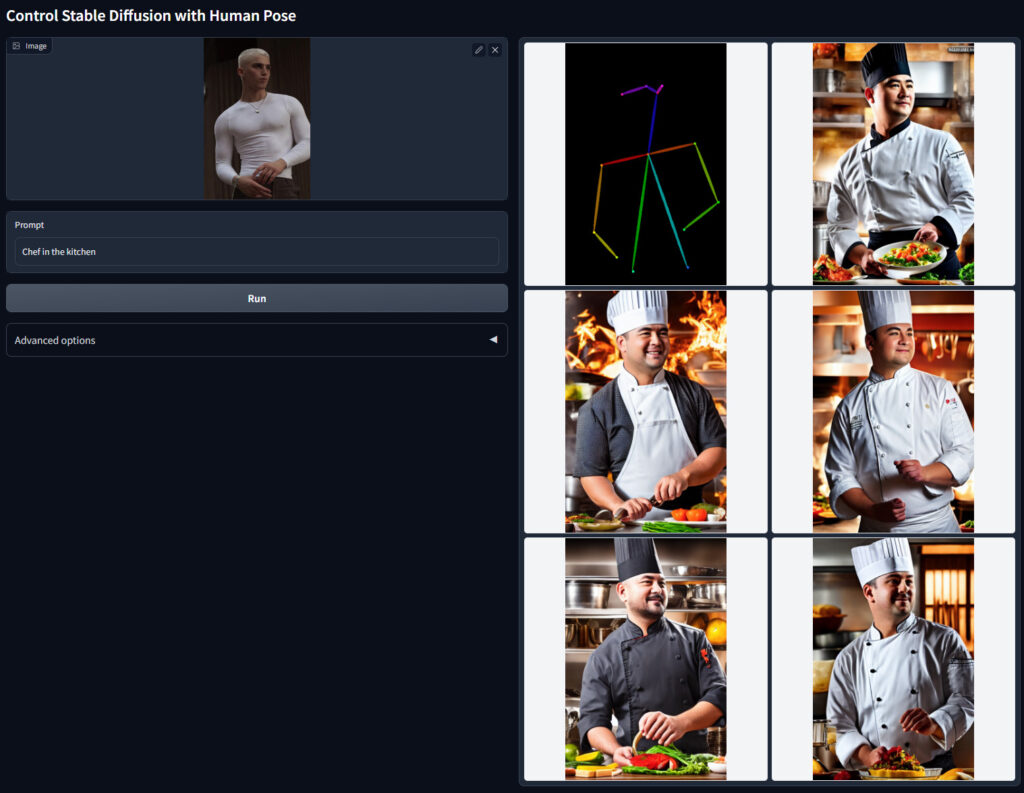
| openpose | OpenPoseは,画像から人体,顔,手足のキーポイントを検出するものです.簡単に説明すると棒人間のようなものを作成します. |
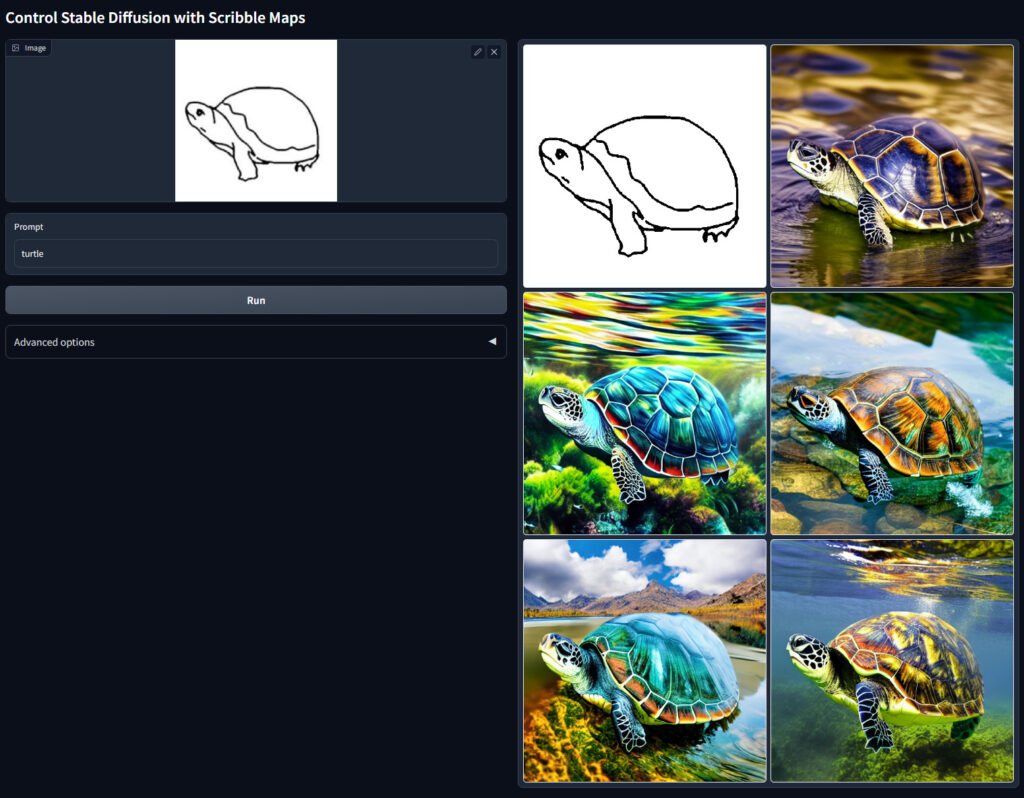
| scribble | scribbleは手書きのような画像からイラストを生成するモデルです. |
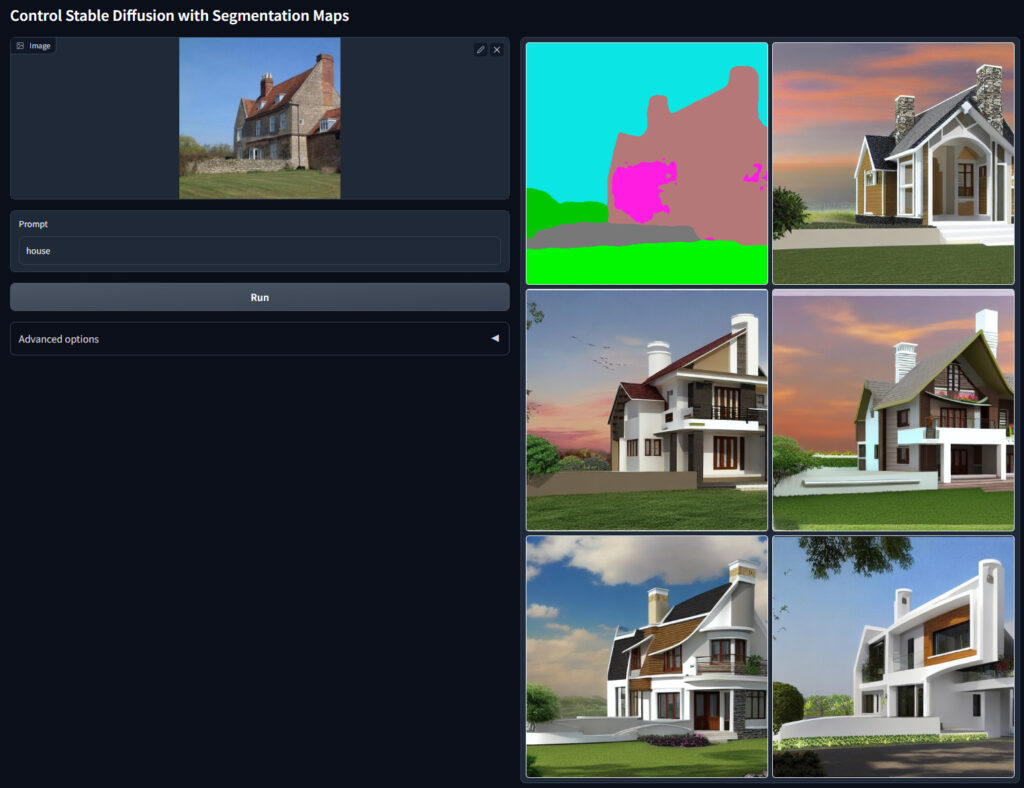
| seg | segはセマンティック・セグメンテーションにより元画像を分類し,それから画像を生成するモデルです. |
cannyはCanny edge detectionというアルゴリズムにより元画像から線画を生成し,その線画から新たにイラストを生成するモデルです.かなり忠実に再現されます.
depthは画像を深度マップに変換し,それをベースに画像を生成するモデルです.奥行きが重要な構図の画像などで使用します.
hedはcannyと同様に線画を作成し,線画からイラストを生成するモデルです.
Cannyとの違いは,輪郭検出のアルゴリズムがHolistically-Nested Edge Detectionアルゴリズムに変更されている点です.
Cannyだと細かい線を検出しますが,HEDの方が大まかな輪郭を抽出してくれます.
元画像によって使い分けると良いでしょう.
mlsdは直線の検出を行うモデルです.背景や構図に使用することが多いです.
normalは,元画像を法線マップに変換し,法線マップから画像を生成するモデルです.(個人的にはdepthの方が使い勝手が良いです)
OpenPoseは,画像から人体,顔,手足のキーポイントを検出するものです.簡単に説明すると棒人間のようなものを作成します.
すなわちopenpose機能は,棒人間から画像を生成するモデルです.ポーズだけを再現できるため,線画(cannyやhed)よりも元画像の制約が少ないため,より柔軟な画像を生成できます.
scribbleは手書きのような画像からイラストを生成するモデルです.
segはセマンティック・セグメンテーションにより元画像を分類し,それから画像を生成するモデルです.
実際に使ってみる
モデルを一通り理解したところで,実際に使用してみます.
元画像は下記のものを使用します.(フリー素材です.こちらからダウンロードできます.)

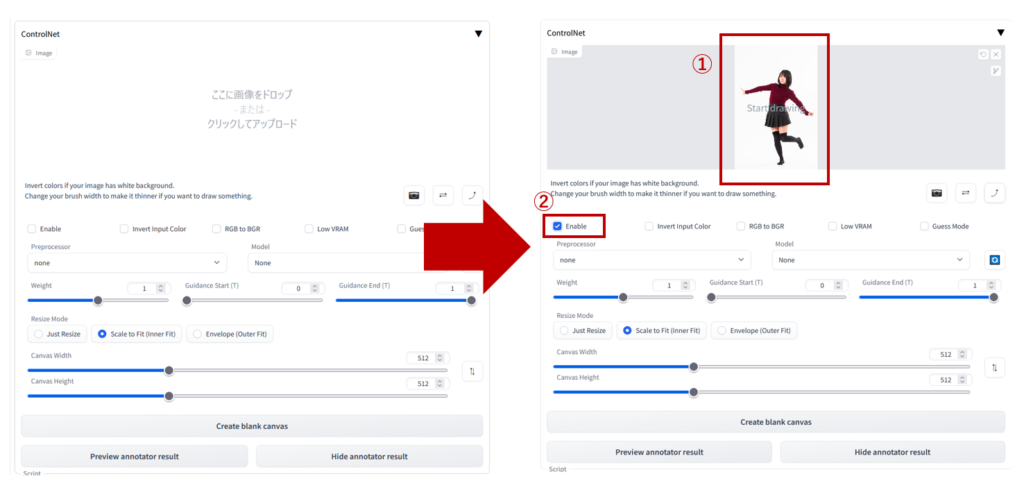
下図のように,画像をドラッグ&ドロップし,「Enable」をチェックします.チェックし忘れるとControlNetが有効化されないので注意してください.
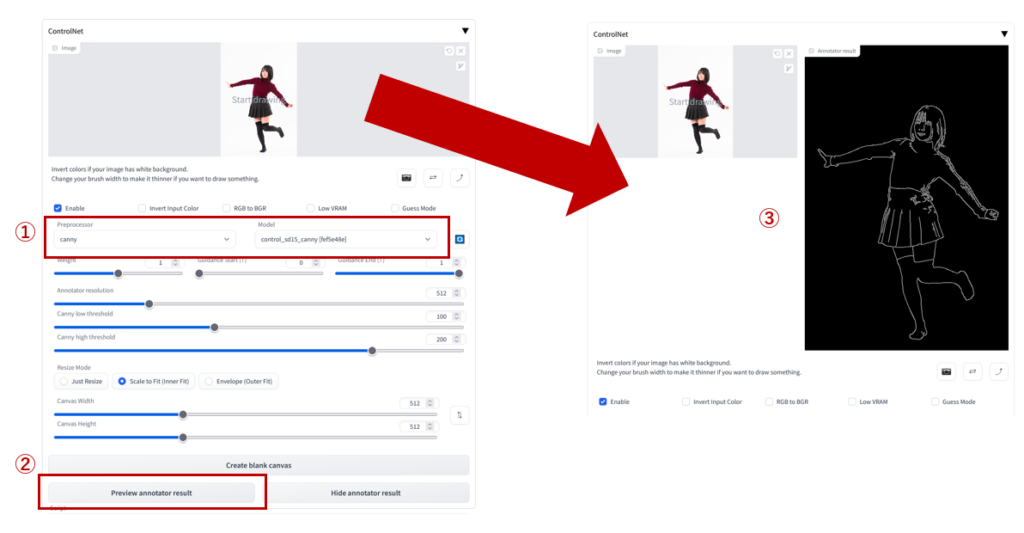
ここでは,cannyを使用します.
① ”Preprocessor”と”Model”をcannyに設定します.② 次に”Preview annotator result”をクリックすると,③ 線画のプレビューが表示されます.
後は普段通り”Generate”をクリックし,画像を生成します.
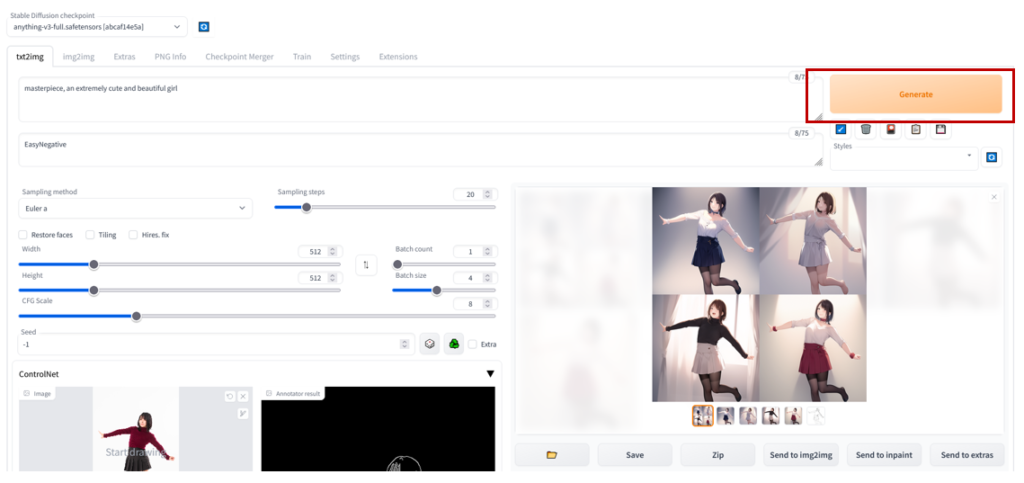
4枚ほど同時出力しましたが,すべて同じ構図となっていることが確認できます.

img2imgでは,ここまでの制御はできなかったので,ControlNetの素晴らしさが良くわかると思います.
この記事では行いませんが,canny以外のモデルも同様の手順でイラストを生成できます.
モデルによる違い
人物のイラスト生成によく使うモデルである「Canny」, 「HED」,「Depth」,「OpenPose」でどのような違いがあるのかを検証してみます.
それぞれのモデルで比較した結果が下記の通りです.



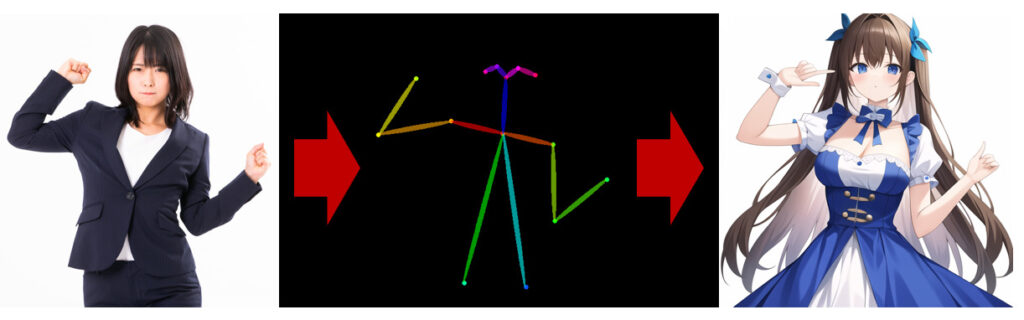
違いはわかりましたか?明らかに異質なものはOpenPoseです.
Canny, HED, Depthでは元画像の服装が生成後の画像に影響を及ぼしているのに対して,OpenPoseはポーズのみが影響を与えていることが分かります.
それぞれでメリットデメリットはもちろん存在しますが,個人的な使い分け目安としては,
・ポーズのみ → OpenPose
・ポーズと服装 → Canny, HED, Depth.さらに,詳細な再現度順にCanny > HED > Depth
というかんじです.
服装や表情はプロンプトでどうにかできるため,OpenPoseが最も柔軟性の高いモデルであることが理解できるかと思います.
ほとんどの場合でControlNetは,img2imgの使い勝手を上回るでしょう.

Multi ControlNet
ControlNetの制御をさらに応用したMulti ControlNetというものがあります.
Multi ControlNetに関しては下記記事を作成しましたのでご覧ください.

GPU
ControlNetを使用する場合,通常のStable Diffusionと比較しGPUの使用率が上昇するため,ある程度性能の良いGPUが必要になってきます.
家庭用である程度有力なGPUを紹介しておきます.わりとメモリを使うので,それなりに積んでいるGPUがおすすめです.
演算能力よりもメモリ搭載量基準で価格を選ぶと良いと思います.
・長時間使用しなければ十分動作する性能のGPU

・快適に扱えるくらいの高性能GPU

・家庭用としては十分すぎるGPU(贅沢品)

さらに高額なNVIDIA A100やH100とかもありますが,もはや家庭用ではありません…